
Table of Contents


The New Engines of the AI Revolution
Think back to the first time a revolutionary technology fundamentally transformed how we live and especially how we work. I am talking about the steam engine, a marvel of engineering that converted heat into mechanical work sparked what we now call the Industrial Revolution. Yet, it wasn't the steam engine alone that reshaped society. It was the factories built around these engines—physical spaces designed to harness this new power at scale—that truly revolutionized production and productivity.
Today, we stand at a similar inflection point. The sophisticated artificial intelligence models like ChatGPT and other Large Language Models (LLMs) have ignited what many recognize as the AI Revolution. These technological marvels can generate human-like text, translate languages, write creative content, and answer questions with remarkable fluency. But just as with steam engines, these AI models alone won't transform our society and economy. The true revolution lies in the construction of "data factories" around them—infrastructure designed to harness AI at scale and make these applications usable by the masses.
This parallel between two revolutionary eras isn't merely an interesting historical observation; it carries profound implications for organizations seeking to thrive in our AI-driven future. Anyone who doesn't just want to consume AI but also wants to use and integrate it into their own products will inevitably have to build a data factory or rent one as a service.
The Spark vs. The Engine: Historical Parallels
The story of the Industrial Revolution begins with a practical problem: how to pump water from increasingly deeper mines. Early steam engines were massive, stationary installations primarily used for this single purpose. While revolutionary in concept, their initial impact was limited by their size, cost, and specific application. The invention itself, while ingenious, was merely the spark.
The transformative power came from factories that could utilize these inventions at scale. Steam engines liberated manufacturing from geographical constraints—factories could now be located anywhere with access to coal, not just near water sources. By 1835,approximately 75% of cotton mills were using steam power, enabling a concentration of production in urban centers. The factory system that emerged represented a fundamental reorganization of work and production, centralizing manufacturing in large facilities where specialized machinery could be operated by semi-skilled workers performing specific tasks.
The statistics tell a compelling story: between 1760 and 1830, cotton goods production in Britain increased by over 1,000 percent. These weren't incremental improvements; they represented a step-change in productive capacity made possible by the combination of steam power and the factory system.
Today's AI models follow a remarkably similar pattern. Despite their impressive capabilities, these models in their raw form have limitations. They require significant technical expertise to deploy, substantial computing resources for inference, and careful management to ensure responsible use. Much like early steam engines—massive, stationary, and limited in application—these raw AI models represent technological potential rather than realized transformation.
The true revolution lies in the data factories being built around them. Unlike traditional data centers that primarily store and process data, AI factories manufacture intelligence at scale, transforming raw data into real-time insights and decisions. They represent a shift from artisanal to industrial production of intelligence—just as physical factories industrialized the production of goods.
To truly generate and deliver that intelligence everywhere, we need the modern equivalent of the power grid and factories – we need data factories.
What Are Data Factories? – Defining the Concept
Data factories are the AI era's answer to the physical factories of the past. In simple terms, a data factory is a large-scale, integrated system (of tools, processes, and people) designed to collect, process, and transform data into AI-driven insights or products. It's the entire assembly line that takes raw data as the input and produces intelligent applications as the output. One AI solutions firm defines an “AI Data Factory” as a framework of tools, processes, and systems where data is the raw material and AI is the transformative agent, producing actionable intelligence as the output.
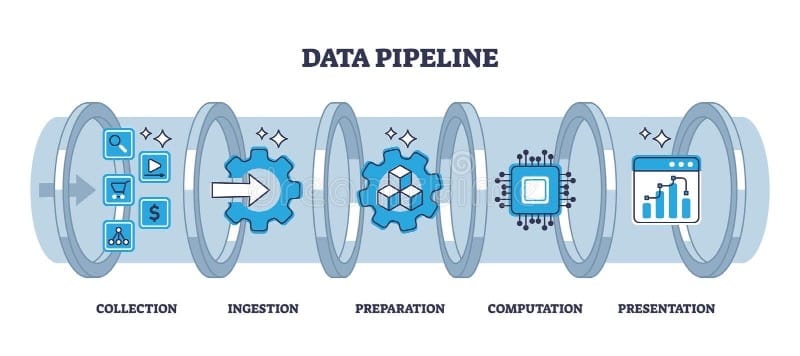
In other words, the data factory acts like an assembly line for data: ingesting raw data from various sources, refining and “manufacturing” it into something useful (trained models, analytics, predictions), and delivering it where it's needed.
To break it down, here are key components typically found in a modern data factory assembly line:
Data Ingestion & Integration: Just as a factory brings in raw materials (coal, iron, cotton) by the ton, a data factory continuously streams in raw data from multiple sources. This could be customer interactions, sensor readings, transaction records, documents – the fuel for AI. Modern pipelines handle enormous volumes (today's global data creation is projected to reach 175 zettabytes by end of 2025! and a variety of formats (text, images, audio, etc.). This stage uses tools to extract data, load it into storage, and often involves real-time data streams.
Data Processing & Preparation: In a traditional factory, raw materials must be refined (iron ore smelted into steel, cotton spun into thread) before use. Likewise, raw data must be cleaned, organized, and labeled. Data factories employ ETL/ELT pipelines (Extract, Transform, Load), data cleaning scripts, and often machine learning for data labeling or augmentation. For example, an e-commerce company's data factory might aggregate customer behavior data from websites, remove duplicates or errors, and structure it into a clean dataset ready for model training. This step ensures high-quality data, which is essential because bad data is like faulty parts on an assembly line – it can ruin the end product.
Model Training & Development: This is the workshop where the AI “product” is actually built. Using the prepared data, the factory trains AI models (or fine-tunes pre-existing ones). This requires heavy computing machinery – think GPU clusters or cloud computing farms – analogous to the powerful steam machines or electricity-driven machines in old factories. In a data factory, engineers might run iterative experiments to improve a model's accuracy, much like refining a prototype on a production line. It's not just one-off training either; leading organizations continuously retrain models as new data comes in, keeping the AI updated (just as a factory might continually improve a product design).
Deployment & Integration (AI Assembly Line Output): Once a model is trained, the next challenge is delivering its intelligence at scale. A data factory handles deployment through APIs, microservices, or other integration methods, so that the model can be used in real applications. If the model is the “engine,” deployment provides the “vehicle” for that engine. For instance, an AI model that predicts maintenance issues in machinery becomes useful only when it's wrapped in a software service that field technicians or IoT devices can query in real time. This stage includes setting up the model on servers (on-premises or cloud), optimizing it for fast inference (similar to tuning a machine for peak efficiency), and making it accessible via an API or app. It's the equivalent of packaging a factory's product and shipping it worldwide.
Monitoring & Ongoing Data Feedback: A factory doesn't operate in the dark – supervisors monitor output quality, and any defects feed back into process improvements. Similarly, data factories implement MLOps (Machine Learning Operations) – monitoring model performance, detecting when predictions go awry or when data drifts over time, and feeding that feedback into the next cycle of data collection or model retraining. This creates a virtuous cycle where the AI system keeps learning and improving. Think of it as the quality control loop and R&D lab of the data factory, ensuring the AI products remain reliable and relevant over time.
Companies like Netflix, Uber, and Google famously built sophisticated data factory-like infrastructures to continuously leverage data and AI in every part of their business. Now, even organizations that aren't tech giants are looking to either build or rent such data factory capabilities, because they see that owning a great “engine” is not enough – you need the factory to harness it.

The Strategic Imperative: Build or Rent?
During the Industrial Revolution, a business faced a pivotal decision: do we build our own factory, or do we rely on someone else's capacity? Some companies constructed massive factories to gain a competitive edge; others might rent equipment or outsource parts of their production. In the AI era, organizations face a similar strategic choice with data factories: build or rent?
Building Your Own Data Factory: Large enterprises or tech-forward companies often invest in creating their own robust data infrastructure from the ground up. Building means hiring data engineers to create custom pipelines, investing in data platforms (or using cloud services extensively but architecturally in-house), curating unique datasets, and perhaps even designing proprietary AI models for their specific needs. The advantage of building is control and differentiation. Just as owning your factory allowed you to perfect a proprietary manufacturing process, owning your data factory allows you to tailor AI exactly to your business and potentially develop capabilities competitors can't easily replicate.
Renting or Leveraging Existing Data Factories: The good news is that you don't have to build from scratch to join the AI Revolution. A whole ecosystem of AI infrastructure providers and cloud platforms now offer data-factory-as-a-service. This is akin to renting a fully equipped factory or parts of a factory. For instance, instead of collecting and labeling massive datasets yourself, you can use public datasets or data marketplaces. Instead of training a huge model from scratch, you can use a pre-trained foundation model (like GPT- via OpenAI's API) and fine-tune it to your needs. Many companies opt for a hybrid approach: they “rent” components like storage, compute power, or even entire models via APIs from providers (such as AWS, Azure, Google Cloud, or OpenAI), while focusing their internal efforts on their unique data or use-case-specific tweaks. For example, a startup building an AI-powered customer service agent can call OpenAI's GPT API (renting the model) and integrate it with their own customer conversation data and interface, rather than developing a large model themselves.
Renting greatly lowers the barrier to entry ‒ you can plug into world-class data centers and AI models almost immediately. It's like a small artisan shop in the 1800s suddenly gaining access to a nearby steam-powered mill to amplify its production. However, renting comes with trade-offs: you might be dependent on third-party services (with ongoing costs), and you could be using the same generic AI capabilities as your competitors. The strategic question becomes: which parts of the data factory do we build for competitive advantage, and which parts do we rent for convenience and efficiency? There's no one-size-fits-all answer. A bank might insist on building internal data pipelines for security and compliance, but rent cloud AI services for things like natural language processing. Conversely, a small business might outsource almost everything ‒ using off-the-shelf AI tools ‒ to accelerate digital transformation without heavy investment.
The Assembly Line of AI Services: It's worth noting that “renting” a data factory doesn't mean you lose all customization. Many AI cloud services are modular. You can pick and choose ‒ use a cloud ingestion pipeline here, an automated ML service there, and your own data warehouse in between ‒ effectively assembling a data factory from prefabricated parts. This flexibility means even organizations without deep AI expertise can start assembling their own AI-driven workflows. For example, using a service like Azure Data Factory (as the name suggests) provides a visual pipeline tool for ingesting and transforming data, which can feed into a model hosted on Azure's ML service, and then deployed via an API ‒ all managed through a cloud interface. It's like renting a fully staffed factory floor: you still decide the production process, but the heavy machinery and labor are provided.
We're already seeing a divide: companies with strong data factory capabilities (either in-house or via partners) are turning AI pilot projects into widespread AI-powered products and decisions, while others struggle to move past PowerPoint slides. In fact, a lack of adequate data infrastructure is cited as a major reason so many AI projects fail in enterprises
Why this Matters - The future of Innovation Depends on this Shift
Why put so much emphasis on data factories? Because the future of innovation and competitive advantage in nearly every industry is being reshaped by this shift from standalone AI experiments to integrated AI factories. Here's why this concept matters:
Turning Demos into Deployments: As mentioned, without data factories, many AI initiatives remain stuck in the lab. A bank might build a neat AI model that predicts loan defaults, but without a data factory, that model might never be continuously fed fresh data from the bank's operations, retrained for changing market conditions, or integrated into the loan officers' software. Data factories bridge the gap between potential and production. They enable what's often called “AI at scale.” Instead of an isolated demo that works once, you get an AI-driven process that works a million times a day, reliably. Organizations that master this can automate and optimize processes at a scale that competitors cannot. It's the difference between hand-crafting a single widget versus mass-producing quality goods ‒ a complete game-changer.
Democratizing AI-Powered Innovation: In the Industrial Revolution, once factories and steam power became widespread, even smaller businesses could contract work or use shared facilities ‒ democratizing manufacturing to a degree. Similarly, data factory infrastructure (especially cloud- based services) is democratizing AI. You don't need to be a tech giant to apply LLMs or advanced analytics to your business problems. This opens the door to AI-powered innovation across the board ‒ from agriculture (with AI models monitoring crop health via drone data pipelines) to healthcare (with data factories aggregating patient data to assist in diagnoses) to education (with AI tutors trained on vast curricula). The companies and leaders who recognize that AI is not just a model but an infrastructure play will be the ones to create revolutionary new services. They'll ask: “How can we build a factory around this idea to continuously improve it and deliver it widely?” Meanwhile, those who don't will find themselves akin to pre-industrial artisans ‒ talented perhaps, but unable to compete with industrial scale.
New Business Models & Ecosystems: Just as the Industrial Revolution led to new business models (mass production, global supply chains, railroads to connect factories to markets, etc.), the AI/data factory revolution is spawning new ecosystems. Entire “data supply chains” are emerging ‒ businesses that specialize in data collection (for example, companies that label data or synthesize data), in model hosting, in AI API marketplaces, and more. We're essentially seeing the rise of an AI economy where raw data might be traded like a commodity and refined intelligence is the product. Understanding data factories helps leaders spot opportunities: Do you become a producer of AI (build a factory), a consumer (rent from others), or maybe an AI infrastructure provider yourself? Visionaries are already positioning their companies in this landscape, much like visionary industrialists built not just factories but entire industries around them.
Preparing for the Next Waves: Today it's large language models and image generators; tomorrow it could be AI systems we haven't even imagined yet. Whatever the next “steam engine” of AI is, having a robust data factory in place means you can plug that new breakthrough in and rapidly leverage it. It future-proofs your organization's ability to innovate. The factory can be re-tooled when new technology comes ‒ much easier than starting from scratch. This means the organizations with data factories will adapt faster to technological change, essentially innovating at the speed of AI. In a world where technology cycles are accelerating, that adaptability is priceless.
Lastly, there's an inspiring human element. When routine tasks are automated and insights flow freely thanks to AI, human workers can focus on higher-level creative and strategic work. In the Industrial Revolution, machines took over grueling manual labor and freed humans to do new kinds of jobs. In the AI Revolution, data factories and automation can free us from drudgery like manual data crunching, allowing us to focus on imagination, strategy, and human-centric innovation.
Build the Future, One Data Factory at a Time
The analogy of steam engines and factories gives us a powerful lens to understand today's AI moment. We are indeed in a “steam engine” moment for AI ‒ breakthroughs like GPT- and other AI models are astonishing inventions, lighting a spark of possibility across every field. But to truly ignite an AI Revolution on par with the Industrial Revolution, we must build and support the data factories that can harness these inventions. It's the combination of great engines and great factories that propels society forward.
For innovators, professionals, and leaders, the call to action is clear: think beyond the model. Whether you're a CIO of a large enterprise or an entrepreneur with a bold idea, ask yourself how you can establish the data infrastructure and processes (the pipelines, the platforms, the teams) to continuously leverage AI at scale. How will you ensure your AI isn't a one-off stunt, but a core part of a living, breathing system of innovation? This may mean investing in cloud services, upskilling your workforce in data engineering, forming partnerships for data sharing, or all of the above. The organizations that succeed in this era will be those that treat data as the new coal and oil, AI models as the engines, and AI infrastructure as the new factory floor where value is forged.
The Industrial Revolution taught us that visionary ideas must be matched with visionary execution. The same is true now.
Because at the end of the day, the strength of a thought or an idea is measured by its translation into action.
If you found this perspective valuable, be sure to subscribe to Wismodia for monthly visionary articles that help you navigate and lead in the future that's unfolding. Together, let's build the future, one data factory at a time.
References
-
Cartwright, M. (2023). The Steam Engine in the British Industrial Revolution. World History Encyclopedia. https://www.worldhistory.org/article/2224/the-steam-engine-in-the-british-industrial-revolution/
-
Fountaine, T., McCarthy, B., & Saleh, T. (2019). Building the AI-Powered Organization. Harvard Business Review. https://hbr.org/2019/07/building-the-ai-powered-organization
-
Corbo, J. et al. (2021, Oct 13). Scaling AI Like a Tech Native: The CEO’s Role. McKinsey & Company. https://www.mckinsey.com/capabilities/quantumblack/our-insights/scaling-ai-like-a-tech-native-the-ceos-role
-
Will AI Disrupt Your Business? Key Questions to Ask. MIT Sloan Management Review (2025). https://sloanreview.mit.edu/article/will-ai-disrupt-your-business-key-questions-to-ask/
-
The Race to Harness AI in Enterprise. WIRED (2024). https://www.wired.com/sponsored/story/the-race-to-harness-ai-in-enterprise/
-
Jensen Huang Wants to Make AI the New World Infrastructure. WIRED (2024). https://www.wired.com/story/big-interview-nvidia-jensen-huang-2024/
-
Iansiti, M., & Lakhani, K. R. (2020). Competing in the Age of AI: Strategy and Leadership When Algorithms and Networks Run the World. Boston, MA: Harvard Business Review Press. https://store.hbr.org/product/competing-in-the-age-of-ai-strategy-and-leadership-when-algorithms-and-networks-run-the-world/10272
Last edited: May 8, 2025 (Added Podcast Version of the Article)